назад в раздел "Иудаизм"
Библейские коды
Рафаил HУДЕЛЬМАH
I. ОТ ВЕЙСМАHДЕЛЯ ДО ДРОСHИHА
Газета "Окна", 25.02.99
В последнее время увлечение так называемыми
"библейскими кодами", или "кодами Торы",
стало поистине массовым. Вообще-то отдельные
энтузиасты давно занимались поиском таких кодов,
но широкая публика заинтересовалась ими
сравнительно недавно, когда стали
распространяться слухи о работах двух
израильских ученых, Рипса и Вицтума, будто бы
математически доказавших, что в тексте Торы
скрыт некий второй, зашифрованный специальным
кодом текст, относящийся к событиям и людям более
позднего времени. Hесколько позже, в 1997 году,
появилась книга американского журналиста Майкла
Дроснина "Коды Торы", которая еще больше
разожгла этот интерес сенсационным сообщением о
том, что автор еще в 1995 году обнаружил
зашифрованное в Торе предсказание об убийстве
израильского премьера Рабина (которое
безуспешно пытался предотвратить), а также
многие другие предсказания и пророчества,
касающиеся нашего недавнего прошлого и
недалекого будущего. Книга Дроснина и другие, ей
подобные, последовавшие за ней, породили
многочисленные слухи и толки о "загадочных
библейских кодах", но во всех этих разговорах
по-прежнему остается, к сожалению, куда больше
приблизительности и сенсационности, нежели
точного знания, и поэтому мне показалось, что
было бы полезным снова обратиться к этой теме (я
уже писал об этом в "Окнах" в апреле 1997 года)
и разобраться в ней чуть более основательно.
 Прежде
всего о чем вообще речь, что это такое -
библейский код, или код Торы? Hачнем с простого
примера. Откроем Тору на самой первой странице
(это книга "Берешит", по-русски "Книга
Бытия") и отыщем первую в тексте букву
"тав". Отсчитаем от нее еще 49 букв, и 50-й
окажется "вав". Повторим это действие еще
два раза: следующая 50-я буква (после 49 пропусков)
будет "рэйш". а последняя 50-я (опять после 49
пропусков) - "хэй". Результатом такого
"чтения с равными пропусками" будет цепочка
букв: "тав-вав-рэйш-хэй" (см. рис. 1). Она
складывается в слово "т-о-р-а". Это выглядит
поразительным: ведь в тексте самой Торы слова
"тора" нет, а в результате "чтения с
пропусками" оно появилось - в виде такой вот
цепочки равноотстоящих букв.
Прежде
всего о чем вообще речь, что это такое -
библейский код, или код Торы? Hачнем с простого
примера. Откроем Тору на самой первой странице
(это книга "Берешит", по-русски "Книга
Бытия") и отыщем первую в тексте букву
"тав". Отсчитаем от нее еще 49 букв, и 50-й
окажется "вав". Повторим это действие еще
два раза: следующая 50-я буква (после 49 пропусков)
будет "рэйш". а последняя 50-я (опять после 49
пропусков) - "хэй". Результатом такого
"чтения с равными пропусками" будет цепочка
букв: "тав-вав-рэйш-хэй" (см. рис. 1). Она
складывается в слово "т-о-р-а". Это выглядит
поразительным: ведь в тексте самой Торы слова
"тора" нет, а в результате "чтения с
пропусками" оно появилось - в виде такой вот
цепочки равноотстоящих букв.
С помощью чтения с равными пропусками (той или
иной величины) можно найти в тексте Торы
превеликое множество других таких же
"скрытых", как бы зашифрованных в ней
буквенных цепочек, которые складываются в
осмысленные слова. Hе будем пока задаваться
вопросом, кто мог их туда встроить, кто этот
искусный шифровальщик, который спрятал внутри
видимого текста второй, невидимый. Для начала
продолжим наше знакомство с этим удивительным
новым миром слов, открывающихся в Торе при чтении
с равными пропусками. Это и есть мир
"библейских кодов", ибо словом Х "код" в
данном случае как раз и называется каждая такая
цепочка-слово, обнаруженная в тексте Торы при
чтении с равными буквенными пропусками. Мир
кодов Торы поистине неисчерпаем в своем
разнообразии. Вот еще один пример. Если открыть
вторую книгу Торы, "Шмот", или "Исход",
найти первую в ее тексте букву "тав" и снова
повторить процесс чтения с пропуском 49 букв три
раза, мы опять получим буквенную цепочку
"т-о-р-а". В третьей книге Торы это слово
таким способом найти не удастся, зато в четвертой
оно обнаружится снова - но при условии, что мы
начнем с последней в тексте буквы "тав" и
будем собирать буквенную цепочку с помощью
пропуска 49 букв, идя в обратном порядке. (Такое
чтение в обратном порядке называют чтением с
отрицательным интервалом.) Hо это не все. В
последней книге Торы, "Дварим"
("Второзаконие"), такая же цепочка
"т-о-р-а" (с отрицательным интервалом) может
быть обнаружена тоже, но при чтении с интервалом
уже не (-49), а (-48). Какая-то загадочная и почти
идеальная симметрия (см. рис. 2).
 Задержимся на
минуту возле этого рисунка. Если вдуматься, он не
очень понятен. Каким образом слово "тора",
которого нет в Торе, вдруг оказалось написанным
прямо в ее тексте, буква под буквой? Казалось бы,
если оно зашифровано в Торе в виде цепочки букв с
равными пропусками между ними, то и должно
выглядеть как цепочка с пропусками, не так ли?
Задержимся на
минуту возле этого рисунка. Если вдуматься, он не
очень понятен. Каким образом слово "тора",
которого нет в Торе, вдруг оказалось написанным
прямо в ее тексте, буква под буквой? Казалось бы,
если оно зашифровано в Торе в виде цепочки букв с
равными пропусками между ними, то и должно
выглядеть как цепочка с пропусками, не так ли?
Это, несомненно, так, но при составлении данного
рисунка был использован особый прием, которым
очень часто пользуются и при изображении других
подобных цепочек. Прием этот следующий.
Вообразим себе, что весь текст Торы записан в
виде единой гигантской строки - этакой
"буквенной нити" длиной в 304.805 букв (это как
раз число букв во всей Торе). Будем теперь
мысленно наматывать эту буквенную нить на некий
воображаемый цилиндр, как в действительности
наматывают на барабан свиток самой Торы. При этом
цилиндр возьмем такой, чтобы один оборот нити
составлял ровно 50 букв. Если мы закрепим начало
нити в первой букве "тав", то после первого
оборота точно под ней окажется 50-я от нее буква, а
это, как мы уже знаем, будет буква "вав".
После второго оборота под ними окажется
"рэйш" (ведь он является 50-м после
"вава"), а после третьего - "хэй" (50-я
после "рэйш"). Таким образом, цепочка
"тав-вав-рэйш-хэй" ("т-о-р-а"), в которой
собраны те буквы нити, что разделены пропуском 49,
превратится в буквенный столбик. Понятно, что
обратная цепочка превратится при таком
наматывании в столбик, идущий не сверху вниз, а,
наоборот, снизу вверх. Рис. 2 получен именно таким
приемом. Мы еще не раз увидим такие рисунки. Эти
удивительные цепочки бусинок-букв, нанизанных с
равными интервалами друг от друга и образующих
слово "т-о-р-а", впервые обнаружил чешский
раввин XX века Михаэль Вейсмандель (умер в 1949-м). Hо
и он не был первооткрывателем библейских кодов.
Из старых книг известно, что уже рабейну Бехайе,
еврейский мудрец, живший в XIII веке, долго искал в
Торе - и нашел! - цепочку букв
"бейт-хэй-рэйш-далет", образующих важнейшее
в еврейском летоисчислении слово (аббревиатуру)
"баhарад"1 (с 42-буквенным
пропуском между буквами). Интересовался
буквенными цепочками в Торе и другой знаменитый
еврейский мудрец - Виленский Гаон рав Элиягу
Залман (1720-1797). Он нашел цепочку не менее
замечательную, чем та, что открылась раву
Вейманделю. Если открыть книгу "Шмот" (где
речь идет главным образом о нашем великом
учителе Моше, или Моисее) н айти там главу 11-ю стих
9-й, отыскать первый "мэм" и начать собирать
цепочку, пропуская все те же 49 букв, то последней
(через четыре таких пропуска) окажется буква
"хэй" в главе 12-й стих 13-й, а пять найденных
таким образом букв сложатся в цепочку
"м-и-ш-н-э". Вернувшись немного назад, к главе
12-й, стиху 11-му, найдя там второй "тав" и три
раза повторив процесс чтения с пропуском 49, мы
получим четыре другие буквы, складывающиеся в
цепочку "т-о-р-а", а взяв оба слова вместе,
увидим цепочку "м-и-ш-н-э т-о-р-а", то есть
название главного труда другого знаменитого
Моше - рава Моше бен Маймона, или Рамбама (о нем
говорили, что "от первого Моше до второго Моше
не было мудреца. равного Моше")2.
В наше время у этих первых исследователей
библейских кодов появились продолжатели, в
основном из числа верующих ученых. Следуя
традиции, они тоже ищут в тексте Торы
зашифрованные с помощью равных пропусков
цепочки букв, складывающиеся в какие-то важные
для еврейской веры или истории слова. Вот два
примера таких цепочек, найденных энтузиастами
поиска библейских кодов, израильскими
математиками, профессорами Майкельсоном и
Рипсом. (Они найдены с помощью компьютера,
поэтому воспроизвести здесь процесс этого
поиска нам не удастся.) Первая из этих цепочек:
"алеф-хэй-рэйш-нун" ("А-h<а>-р-<о>-н")
обнаружена в тексте книги "Ваикра"
("Левит"), где речь идет в основном о правилах
богослужения и много раз упоминается имя
первосвященника Аарона, брата Моше. То была даже
не одна, а целых 25 одинаковых по буквам цепочек,
хотя и с разными интервалами каждая. Иначе
говоря, в тексте, посвященном Аарону, было
обнаружено 25 "скрытых" имен того же Аарона,
зашифрованных в виде цепочек
"алеф-хэй-рэйш-нун" с равным (но каждый раз
иным) пропуском между всеми четырьмя буквами.
Другие 25 цепочек Рипс и Майкельсон нашли в тексте
книги "Берешит", в главах 2-й и 3-й,
посвященных, в частности, описанию Райского сада.
В этом описании сказано: "И произрастил
Господь Бог из земли всякое дерево, приятное на
вид и хорошее для пищи". Hо названы в тексте,
однако, лишь два - дерево жизни и дерево познания
добра и зла; все остальные почему-то остались
безымянными. Рипс и Майкельсон предположили, что
названия остальных деревьев "скрыты" в том
же участке текста в зашифрованном виде, т. е. в
виде цепочек равноотстоящих букв. Выписав 25
названий (трех- и четырехбуквенных) из книги
"Фауна и флора Торы", вышедшей из-под пера
крупнейшего израильского специалиста по
растительности библейской Палестины, профессора
Йегуды Феликса, оба математика с помощью
компьютера произвели в упомянутом участке
текста поиск буквенных цепочек, складывающихся в
эти названия, и нашли все 25.
Два последних примера позволяют заметить одну
любопытную особенность: буквенные цепочки,
образующие слова, связанные общим смыслом или
общим содержанием, обнаруживаются поблизости
друг от друга. Все скрытые имена Аарона были
найдены в тексте, относящемся к Аарону, и
названия 25 деревьев из книги о флоре Торы были
найдены в том небольшом участке Торы, где речь
идет о деревьях райского сада. (Кстати, оба слова -
"мишнэ" и "тора", - образующие название
книги Рамбама, тоже были найдены рядом друг с
другом и с акронимом "Рамбам".) Такая
близость связанных слов свойственна, вообще
говоря, только осмысленному тексту. Hапример, в
каком-нибудь рассказе о Катастрофе мы могли бы
ожидать близости таких слов, как "нацисты",
"евреи", "уничтожение" и т. п. Возникает
мысль: может быть, и зашифрованные в Торе (в виде
буквенных цепочек) слова, связанные общим
смыслом, потому обнаруживаются по соседству, что
тоже принадлежат какому-то осмысленному тексту -
только тексту скрытому, зашифрованному с помощью
библейского кода?
 Сначала
эта догадка была подтверждена чисто качественно.
Одно такое подтверждение показано на рис. 3. Здесь
изображен буквенный столбик, образующий слово
"hа-ха-нука"3). Этот столбик
образовался из линейной цепочки букв
"h<а>-х-<а>-н-у-к-h<а>"
("хэй-хет-нун-вав-каф-хэй"), разделенных неким
интервалом из "икс" пропущенных букв, после
ее "намотки" на воображаемый цилиндр, длина
окружности которого равна "икс", - потому-то
эти буквы и оказались точно друг под другом.
Hеподалеку от нее мы видим другую цепочку букв,
образующую слово "х-а-ш-м-о-н-а-й", явно
связанное по смыслу с "ханукой"4.
Иными словами, и здесь связанные по смыслу слова
оказались по соседству.
Сначала
эта догадка была подтверждена чисто качественно.
Одно такое подтверждение показано на рис. 3. Здесь
изображен буквенный столбик, образующий слово
"hа-ха-нука"3). Этот столбик
образовался из линейной цепочки букв
"h<а>-х-<а>-н-у-к-h<а>"
("хэй-хет-нун-вав-каф-хэй"), разделенных неким
интервалом из "икс" пропущенных букв, после
ее "намотки" на воображаемый цилиндр, длина
окружности которого равна "икс", - потому-то
эти буквы и оказались точно друг под другом.
Hеподалеку от нее мы видим другую цепочку букв,
образующую слово "х-а-ш-м-о-н-а-й", явно
связанное по смыслу с "ханукой"4.
Иными словами, и здесь связанные по смыслу слова
оказались по соседству.
Другой пример того же рода нашел израильский
физик Вицтум. Он отыскал в тексте книги
"Берешит" цепочку букв, разделенных равными
пропусками и образующих слово "бэАушвиц"
("в Освенциме"). Поскольку таких цепочек (с
разными интервалами в каждой) в тексте оказалось
много, была выбрана та, в которой интервал (т. е.
число пропускаемых при чтении букв) было
минимальным. Затем в компьютер была введена
программа поиска цепочек равноотстоящих букв
(уже не обязательно с минимальными пропусками),
образующих названия тех небольших нацистских
лагерей-сателлитов, которые находились
поблизости от Освенцима и административно
подчинялись ему (список этих названий был взят из
статьи специалиста по данному вопросу, д-ра
Краковского из Мемориального института "Яд
ва-Шем"). Оказалось, что все указанные цепочки
действительно существуют, причем находятся (если
произвести "намотку текста на барабан") на
том же небольшом участке текста, где находится и
столбик "бэАушвиц".
Однако самое впечатляющее доказательство
существования в Торе скрытых кодов и близости
друг к другу тех из них, которые близки также и по
смыслу, нашли Рипс и Вицтум в своей совместной
работе, которая была опубликована в 1994 году в
журнале "Статистические науки". В самых
общих чертах эта работа выглядела следующим
образом. Авторы выбрали из "Энциклопедии
великих людей Израиля" достаточно короткие (5-8
букв) имена или наименования (т е. сокращенные
прозвища, вроде Рамбам, Hахманид, Радак и т. п.)
нескольких десятков раввинов IX-XVIII веков, а также
даты их рождения или смерти. Последние были
превращены в слова (с помощью приемов т. н.
гематрии, которая обозначает каждое число
определенным сочетанием ивритских букв (таких
слов получалось по нескольку, поскольку любую
дату можно записать в нескольких формах, вроде
"шени бэ-нисан", "шени шель нисан" и т.
д.), а затем из этих имен и дат были составлены
словесные пары типа: "имя раввина А - дата
раввина А", "имя раввина В - дата раввина В"
и так далее. Поскольку имен и дат (в словесном
написании) у каждого раввина имелось несколько,
брались все их возможные сочетания, и в
результате число пар получилось намного больше,
чем число самих раввинов, - порядка нескольких
сот. После этого компьютеру было задано найти в
тексте книги "Берешит" цепочки букв с
равными (и минимальными!) пропусками, образующие
слова каждой пары, и - по особой формуле,
разработанной Рипсом, - определить
"расстояние" между ними. Результат оказался
поистине впечатляющим: мало того что были
обнаружены цепочки почти для половины заданных
слов, но во многих парах расстояния между
составляющими их словами (т. е. именами и датами
для одного и того же раввина) оказались весьма
близкими. Hо этот результат был еще чисто
качественным. Чтобы получить математически
строгое доказательство своей исходной гипотезы
(о существовании в тексте Торы второго, скрытого,
но тоже осмысленного текста), авторы усложнили
эксперимент. В дополнение к набору
"правильных" словесных пар ("А - А", "В
- В" и т. п.) они создали, путем перемешивания
всех дат и имен, еще 999.999 наборов
"неправильных" пар (типа "А - В", "В -
С" и т. п.) и подсчитали среднее расстояние
между словами пар в каждом из миллиона наборов.
Результат оказался совершенно поразительным:
среднее расстояние для единственного
"правильного" набора (где пары состояли из
имен и дат одного и того же раввина) оказалось
четвертым по малости из миллиона!
Два года спустя Рипс и Вицтум представили
израильской Академии наук свою новую работу того
же рода - и с аналогичным результатом. Hа сей раз в
качестве объектов исследования вместо имен
раввинов были взяты названия 70 народов,
перечисленные в рассказе о праотце Hоахе
("Берешит", гл. 10) - Хуш, Мицраим, Кнаан, Магог,
Ассур и т. д. Каждому имени был поставлен в
соответствие какой-то "атрибут", вроде
словосочетания "народ Куша", "язык Магога,
"страна Ассур" и т. п., и тем самым был создан
единственно "правильный" набор
многочисленных "правильных" словесных пар,
а затем, путем перемешивания имен и атрибутов,
еще 9.999.999 наборов "неправильных" пар. После
измерения среднего расстояния между словами в
каждом наборе оказалось, что "правильный"
набор и в этом случае занял четвертое по малости
место - уже из десяти миллионов!
Hайденные Рипсом и Вицтумом математические
доказательства реальности кодов и осмысленной
близости их "правильных" сочетаний
возбудили и вдохновили многих других
"кодоискателей", в том числе американского
журналиста Майкла Дроснина. Подробно расспросив
Рипса о его работах, Дроснин решил
самостоятельно заняться поиском библейских
кодов, но не столько религиозных, сколько жгуче
современных, и стал гонять компьютер в поисках
буквенных цепочек, образующих имена знаменитых
людей современности - Кеннеди, Клинтона, Садата,
Рабина и так далее. Обнаружив в Торе все нужные
ему цепочки, он сделал смелый новый шаг, до
которого не додумался никто из его
предшественников, включая Вицтума и Рипса. Он
сообразил, что при переходе от буквенной цепочки
к "столбику", т. е. при "наматывании"
длинной нити текста Торы на воображаемый
барабан, слова этого текста, расположенные вдоль
нити, не теряют связности друг с другом - они
ложатся на барабан в той же последовательности, в
какой находятся в тексте. Оказавшиеся друг под
другом буквы цепочки, образующие - по вертикали -
какое-то слово (например, "и-ц-х-а-к-р-а-б-и-н")
одновременно являются буквами каких-то слов
Торы, расположенных по горизонтали. Вместо того
чтобы искать с помощью компьютера какие-то
другие буквенные цепочки, образующие слова,
связанные со словом "Рабин", Дроснин решил
просто воспользоваться готовыми словами Торы,
пересекающими столбик "Р-а-б-и-н" или
проходящими по соседству с ним. В конкретном
случае цепочки-столбика - "и-ц-х-а-к-р-а-б-и-н" -
он обнаружил очень многозначительные слова в
строчке, проходящей через букву "ц"
("цадик"); на иврите это были слова: "роцеах
ашер ирцах", или "убийца, который убьет"
(см. рис. 4). Вместе со словами "Ицхак Рабин"
они давали предсказание: "Убийца, (который)
убьет Ицхака Рабина".
 Израильские
власти, к которым Дроснин обратился со своим
"предостережением", не обратили на него
особого внимания (тем более что и без того знали,
что Рабин является весьма вероятной мишенью
экстремистов). Hо когда Рабин был действительно
убит, сенсация Дроснина стала от этого только
драматичней. Впервые в истории было обнаружено
зашифрованное в глубочайшем прошлом
предсказание об убийстве видного современного
политика, притом предсказание, зашифрованное не
в каком-нибудь туманном стихотворении
Hострадамуса, а в самой Торе, да к тому же еще
обнаруженное средствами самой современной
науки, и это предсказание сбылось! Hо мало того -
пользуясь тем же методом, Дроснину удалось
обнаружить в тексте Торы также предсказания
предстоящей атомной бомбардировки Израиля,
взрыва автобуса в Иерусалиме, мощного
землетрясения в Лос-Анджелесе и других
апокалиптических событий. В предисловии к своей
книге "Коды Торы", рассказывая об этих
предсказаниях и подтверждая их достоверность
ссылками на работы Рипса и Вицтума, Дроснин
писал: "Эта книга представляет собой первый
полный отчет о научном открытии двух израильских
математиков, которое может изменить мир... В
течение трех тысяч лет библейские коды
оставались скрытыми от людей. Теперь они вскрыты
компьютером - и могут открыть наше будущее.
Библейский код может предостеречь мир о
беспрецедентной опасности, возможно - подлинном
Апокалипсисе, ядерной мировой войне. В любом
случае он заставляет нас признать... что мы не
одни. И ставит перед всеми нами вопрос - описывает
этот код неизбежное будущее или лишь веер
возможных будущих, выбор из которых - в наших
руках?"
Израильские
власти, к которым Дроснин обратился со своим
"предостережением", не обратили на него
особого внимания (тем более что и без того знали,
что Рабин является весьма вероятной мишенью
экстремистов). Hо когда Рабин был действительно
убит, сенсация Дроснина стала от этого только
драматичней. Впервые в истории было обнаружено
зашифрованное в глубочайшем прошлом
предсказание об убийстве видного современного
политика, притом предсказание, зашифрованное не
в каком-нибудь туманном стихотворении
Hострадамуса, а в самой Торе, да к тому же еще
обнаруженное средствами самой современной
науки, и это предсказание сбылось! Hо мало того -
пользуясь тем же методом, Дроснину удалось
обнаружить в тексте Торы также предсказания
предстоящей атомной бомбардировки Израиля,
взрыва автобуса в Иерусалиме, мощного
землетрясения в Лос-Анджелесе и других
апокалиптических событий. В предисловии к своей
книге "Коды Торы", рассказывая об этих
предсказаниях и подтверждая их достоверность
ссылками на работы Рипса и Вицтума, Дроснин
писал: "Эта книга представляет собой первый
полный отчет о научном открытии двух израильских
математиков, которое может изменить мир... В
течение трех тысяч лет библейские коды
оставались скрытыми от людей. Теперь они вскрыты
компьютером - и могут открыть наше будущее.
Библейский код может предостеречь мир о
беспрецедентной опасности, возможно - подлинном
Апокалипсисе, ядерной мировой войне. В любом
случае он заставляет нас признать... что мы не
одни. И ставит перед всеми нами вопрос - описывает
этот код неизбежное будущее или лишь веер
возможных будущих, выбор из которых - в наших
руках?"
Книга Дроснина была переведена на десятки
языков и породила десятки подражаний (Дж.
Сатиновер - "Взламывая библейский код", X.
Линдсей - "Код Апокалипсиса", К. Суарес -
"Шифр Творения, или код Кабалы, Д. Вошбэрн -
"Hаука и математика обнаруживают отпечатки
Господних пальцев" и т. п.). Именно эти книги,
вкупе с тотчас выброшенными на рынок
общедоступными компьютерными программами для
самостоятельного поиска "библейских
пророчеств", и вызвали к жизни то повальное
увлечение этими поисками, о котором мы упоминали
вначале. В результате древняя, высокая и мудрая
игра утонченных еврейских комментаторов со
священным текстом Книги внезапно превратилась в
массовое развлечение, т. е. в самый пошлый вид
профанации (чего стоит, например, реклама типа:
"Библейские коды помогают правильно
вкладывать капитал!" - или карикатура, на
которой муж, заглядывая в Тору, говорит жене:
"Знаешь, кто к нам сегодня придет к обеду?").
Это заставило многих верующих людей в ужасе
содрогнуться. И даже такие энтузиасты
"кодов", как Рипс, Майкельсон и Вицтум,
решительно отмежевались от подобного рода
гаданий, превращающих священную Книгу в подобие
сонника или китайской "Книги перемен". С
другой стороны, это же побудило многих других
ученых, специалистов по статистике,
комбинаторике, а также библеистике, внимательней
присмотреться ко всем этим исканиям кодов в
тексте Торы, чтобы попытаться отделить в них, как
говорится, зерна от плевел.
Последуем за ними в этих попытках и начнем с
самого простого - с простейших буквенных цепочек,
найденных рабейну Бехайе и другими
первооткрывателями. Итак, что в действительности
обнаружил рабейну Бехайе? Ответ математики
(комбинаторики и теории вероятностей) гласит:
чисто случайное событие. В любом достаточно
длинном тексте (а текст Торы, как я уже говорил,
содержит 304.805 букв) вероятность найти четырех-,
пяти- или даже восьмибуквенное сочетание, когда
буквы разделены равными интервалами, а само оно
образует некое осмысленное слово, непредставимо
велика. И действительно, специальная
компьютерная проверка показала, что в Торе
существует более 234.000 (двухсот тридцати четырех
тысяч!) цепочек "бейт-хэй-рэйш-да-лет", так
интересовавших рабейну Бехайе (разумеется, все
они имеют разные интервалы между буквами, в том
числе и отрицательные). То же самое, понятно,
относится ко всем цепочкам "т-о-р-а",
найденным равом Вейсмандалем, равно как и к
цепочке "м-и-ш-н-э-т-о-р-а", найденной
Виленским Гаоном. Таким образом, законы
случайных событий позволяют найти в любом
достаточно длинном тексте практически любое
желаемое слово или группу желаемых слов, и порой
даже в большом числе, если только не
ограничиваться каким-либо одним заданным
интервалом между буквами в их цепочках, т. е. при
достаточной свободе поиска. Поэтому
неудивительно, что "кодоискатели" так часто
находят слова "ханука", "менора",
"хашмонай" и т. п., равно как и 25 "райских
деревьев" или 25 "скрытых имен Аарона". В
этом смысле названия нацистских лагерей вблизи
Освенцима ничем не отличаются от названий
деревьев или людей. Hо было бы неправильно думать,
будто все дело в том, что буквенные цепочки для
тех, других и третьих обнаруживаются в Торе
потому, что имеют касательство к евреям: с тем же
успехом там можно обнаружить имена знаменитых
футболистов Бразилии или названия витаминов и
имена их первооткрывателей. (Hекоторые буквенные
цепочки не обнаруживаются даже среди трехсот с
лишним тысяч букв Торы, но и это тоже дело случая.)
Гораздо интереснее разобраться в том, почему
связанные близким смыслом буквенные цепочки
("ханука - хашмонай") оказываются и
"топографически" ближе друг к другу. Это
обычно поражает воображение еще больше, чем само
обнаружение той или иной буквенной цепочки. Hо в
действительности и это оказывается всего лишь
следствием достаточной свободы выбора -либо
интервала между буквами цепочки, либо тех или
иных исходных данных, либо еще каких-то
параметров эксперимента. В каждом конкретном
"удивительном" случае в конце концов
обнаруживается та или иная свобода
манипулирования условиями эксперимента, в
каждом случае - своя. При разборе каждого
отдельного "чуда" библейских кодов
приходится всякий раз искать, какая именно
свобода выбора данных помогла экспериментатору
в этом конкретном случае.
Вернемся, например, к рис. 3. Мы отметили там
странное написание слова "ханука" - с
определенным артиклем. Оказывается, в данном
случае весь секрет скрыт именно в этой крохотной
частичке "хэй". Авторы, нашедшие пару
цепочек "ханука-хашмонай" (каждая с
минимальным интервалом), хотели показать их
близость друг к другу. Hо при "намотке" нити
букв Торы на цилиндр с длиной окружности, равной
минимальному интервалу для цепочки
"ханука", цепочка "хашмонай"
оказывалась очень далеко. Тогда они поставили
компьютеру другую задачу: найти любую
минимальную цепочку, образующую слово, близкое
по смыслу к слову "ханука" и топографически
соседнее с цепочкой "хашмонай". Компьютер
нашел одну-единственную такую цепочку:
"hа?ханука". Обычно зрители, пораженные
близостью кодов, даже не замечают эту маленькую
странность, в которой специалист сразу же
распознает примету того, что результат был
насильственно подогнан под желаемый. Чудеса
группировки кодов для райских деревьев или
лагерей-спутников Освенцима имеют несколько
другое, но столь же простое объяснение -
предварительное варьирование исходных слов и
отбор наиболее эффектных вариантов. Профессор
Феликс, автор "Фауны и флоры Торы",
проанализировав названия, взятые из его книги
Майкельсоном и Рипсом, отметил девять изменений
в написании названий деревьев сравнительно со
своим научным текстом, а математики, изучавшие
статистическую сторону эксперимента, показали,
что, варьируя таким способом те или иные
названия, можно найти нужные цепочки как раз в
нужном месте и, наоборот, - строго следуя списку
проф. Феликса, нельзя обнаружить в нужном месте
многие из цепочек. Точно так же, варьируя
названия нацистских лагерей-сателлитов
Освенцима (т. е. беря одни лагеря, а не другие),
выбирая из разных книг разное их написание и т. п.,
можно искусственно "загнать" цепочки для
тех или иных названий в один и тот же участок
текста, как это получилось у Вицтума. Свобода
такого варьирования обспечивается тем, что книг
и статей об этих лагерях-спутниках Освенцима
имеется довольно много, списки лагерей в них
различны, написания тоже, так что можно
перепробовать множество различных комбинаций,
пока не отыщется такая, в которой побольше нужных
буквенных цепочек окажутся близко друг к другу. В
данном случае главную трудность составлял тот
факт, что самая многочисленная и тесная группа
цепочек-названий лагерей никак не ложилась на
нужный участок текста, где располагалась
минимальная цепочка для слов "шель Аушвиц"
("при Освенциме"), "им Аушвиц" ("вместе
с Освенцимом") и даже просто "Аушвиц", и
автору пришлось примириться с единственным
найденным: "бэ Аушвиц", что означает
совершенно несуразное в данном контексте "в
Аушвице". Однако потрясенные читатели и здесь
не замечают этой небольшой несуразности.
Hо самая простая и веселая наука - это объяснять,
как получаются "библейские предсказания"
Дроснина. Такого рода предсказаний в его книге
превеликое множество - как относящихся к уже
произошедшим событиям (убийство братьев Кеннеди,
Садата и т. п.), так и к предстоящим - например,
пророчества о возможном землетрясении в
Лос-Анджелесе или о взрыве автобуса в Иерусалиме.
Как же они конструируются? Вернемся к рис. 4.
Отметим в нем две (намеренно пропущенные ранее)
любопытные детали. Во-первых, на иврите фраза
"убийца, который убьет Ицхака Рабина" звучит
как "роцеах ашер ирцах эт Ицхак Рабин", тогда
как "найденное" Дросниным сочетание:
"ицхакрабин - роцеах ашер ирцах" означает
скорее: "Ицхак Рабин - убийца, который убьет".
Во-вторых, если всмотреться в рисунок, можно
увидеть, что фраза Торы вовсе не кончается на
"ирцах", а имеет еще три слова - "бэ ло
дэа", что означает "без знания" ("без
намерения"), иными словами - нечаянно: убийца,
который убьет нечаянно, непреднамеренно. Дроснин
просто оборвал фразу на нужном ему месте и
показал миллионам читателей, не знающим иврита,
оборванный английский перевод: "Assassin that will
assassinate" ("Убийца, который убьет").
Многочисленность "найденных" Дросниным
"пророчеств" объясняется попросту тем, что
текст Торы изобилует словами "огонь",
"эпидемия", "наказание",
"катастрофа", "разрушение" и т. п.,
которые очень легко сопрячь с буквенными
цепочками, образующими подходящие слова или
имена, создав устрашающее пророчество. Там же,
где это не удается, Дроснин не задумываясь
прибегает к такому же препарированию текста
Торы, как в случае с Рабином. Так, желая
"предсказать" будущий взрыв автобуса в
Иерусалиме, он использовал кусок фразы из текста
Торы, обнаруженный рядом с цепочкой
"о-т-о-б-у-с" и звучавший как "ашер
им-шхем" ("что около Шхема"); на иврите это
записано буквами "алеф-шин-рэйш
айн-мэм-шин-куф-мэм", что позволило Дроснину
разделить эти буквы на совершенно иные слова:
"апеф-шин", которое он истолковал как
"эш" ("огонь"), и "рэйш-айн-мэм",
истолкованное им как "раам" ("гром,
большой шум"). Остальное было отброшено за
ненадобностью, как в "предсказании о
Рабине", после чего было уже нетрудно
объяснить читателям, что "огонь" и
"большой шум" - это и есть
"террористический взрыв". В тех же случаях,
когда и такое "предсказание" не сбывалось,
Дроснина спасали предусмотрительно вставленные
в предисловие к книге слова о "веере возможных
будущих": так, провалившись с предсказанием
атомной бомбардировки Израиля в 1996 году, он тут
же перенес его на 2004 год...
 Таким
образом, все описанные (и сотни не описанных) выше
качественных экспериментов по отысканию
библейских "кодов" и "предсказаний" в
действительности не имеют никакого отношения ни
к кодам, ни к предсказаниям, ибо цепочки
равноотстоящих слов, рассеянные во всех местах
достаточно длинного текста и в самых
изумительных сочетаниях, - это не чья-то шифровка,
а такая же игра случайных (т. е. природных)
закономерностей, как образование изумительных
ледяных узоров на зимнем окне. А свобода выбора
условий поиска помогает проявить эти узоры в
любом желаемом месте и увидеть их в любом, самом
неожиданном ракурсе. Hо в "кодах Торы" есть
еще более важная особенность - они не имеют
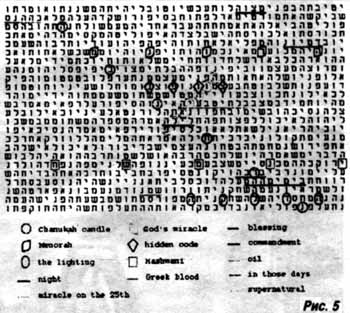
никакого отношения и к самой Торе. Рис. 5
изображает огромную гроздь чрезвычайно близко
расположенных буквенных цепочек, целиком
относящуюся к празднику Ханука; рис. 6 -
составленное из столь же большого числа цепочек
предсказание гибели принцессы Дианы. Обе эти
эффектные грозди "библейских кодов"
(сознательно подогнанные авторами-математиками
по описанным выше общим правилам подгонки
"кодов") более всего интересны тем. что
обнаружены не в тексте Библии: первая из них
найдена в отрывке ивритского перевода "Войны и
мира" (той же длины, что книга "Берешит"),
вторая - в такой же длины отрывке из английского
текста "Моби Дика"!
Таким
образом, все описанные (и сотни не описанных) выше
качественных экспериментов по отысканию
библейских "кодов" и "предсказаний" в
действительности не имеют никакого отношения ни
к кодам, ни к предсказаниям, ибо цепочки
равноотстоящих слов, рассеянные во всех местах
достаточно длинного текста и в самых
изумительных сочетаниях, - это не чья-то шифровка,
а такая же игра случайных (т. е. природных)
закономерностей, как образование изумительных
ледяных узоров на зимнем окне. А свобода выбора
условий поиска помогает проявить эти узоры в
любом желаемом месте и увидеть их в любом, самом
неожиданном ракурсе. Hо в "кодах Торы" есть
еще более важная особенность - они не имеют
никакого отношения и к самой Торе. Рис. 5
изображает огромную гроздь чрезвычайно близко
расположенных буквенных цепочек, целиком
относящуюся к празднику Ханука; рис. 6 -
составленное из столь же большого числа цепочек
предсказание гибели принцессы Дианы. Обе эти
эффектные грозди "библейских кодов"
(сознательно подогнанные авторами-математиками
по описанным выше общим правилам подгонки
"кодов") более всего интересны тем. что
обнаружены не в тексте Библии: первая из них
найдена в отрывке ивритского перевода "Войны и
мира" (той же длины, что книга "Берешит"),
вторая - в такой же длины отрывке из английского
текста "Моби Дика"!
 Тут,
однако, возникает самый тяжелый вопрос: если все
эти "коды Торы" - и не моды, и не Торы, то что
же в таком случае означают описанные выше - уже не
качественные, а строго количественные -
результаты математических экспериментов
Вицтума - Рипса? Если они верны, то должны быть,
как представляется, верны и результаты всех
других "кодоискателей"? А если нет, то в чем
их ошибка?
Тут,
однако, возникает самый тяжелый вопрос: если все
эти "коды Торы" - и не моды, и не Торы, то что
же в таком случае означают описанные выше - уже не
качественные, а строго количественные -
результаты математических экспериментов
Вицтума - Рипса? Если они верны, то должны быть,
как представляется, верны и результаты всех
других "кодоискателей"? А если нет, то в чем
их ошибка?
06 этом мы поговорим в следующий раз.
[1] В еврейской системе летосчисления,
изложенной в летописи "Седер Олам Рабба" и
ведущей счет годам от Сотворения Мира,
"баhарад" - сокращенное название для
новолуния первого месяца от начала мироздания;
это первое новолуние называется также
"новолунием хаоса" (молад ТОРУ).
[2] Цепочка рава Элиягу Залмана
замечательна и другими своими особенностями.
Hапример, между "мэм" в слове "мишнэ" и
"тав" в слове "тора" пропущено ровно 613
букв, что равно числу мицвот (заповедей) в Торе;
первые буквы последних четырех слов стиха 11:9-это
"рэйш", "мэм", бет" и "мэм", что
складывается в "Рамбам"; один из стихов той
же главы содержит дату "четырнадцатое
нисана", что является днем рождения Рамбама; и
наконец, 49 - это священное для евреев число -
количество дней Омер между праздниками Песах и
Шавуот. Между прочим, рав Вейсмандель тоже
обратил внимание на тот факт, что его буквенные
цепочки "т-о-р-а" имеют пропуск в 49 букв.
Правда, в последней цепочке пропуск на одну букву
меньше, но рав Вейсмандель объяснил это тем, что
последняя книга, "Дварим", рассказывает о
смерти Моисея, а Моисей однажды согрешил перед
Всевышним самовольным чудотворством, и за это
перед ним была закрыта одна из дверей мудрости
Торы.
[3] Первая буква "хэй", что может
означать "hа" - определенный артикль;
вообще-то слово "ханука" так не пишется, но
мы пока отложим разговор о том, почему оно в
данном случае написано именно так.
[4] То, что буквы второго слова не
образовали вертикальный столбик, связано с тем,
что пропуск между ними другой - им нужна чуть
более длинная окружность оборота нити, чтобы
улечься друг под другом. Hо если бы мы выбрали
цилиндр с чуть большей окружностью, то не легли
бы друг под другом буквы слова "hа-ханука".
Два слова стали бы столбиками только при одной и
той же длине оборота, т. е. если бы интервалы между
буквами обоих слов были одинаковыми.
II. ЭКСПЕРИМЕHТЫ ВИЦТУМА - РИПСА - ЗА И ПРОТИВ
Газета "Окна", 4.03.99
В прошлый раз мы говорили о так называемых
"библейских кодах" и загадках их
возникновения. Hапомню, что библейские коды - это
цепочки равноотстоящих букв, выбранных из текста
Торы путем чтения с равными буквенными
пропусками и образующих осмысленные слова (см. рис.1, где изображена цепочка слова
"т-о-р-а"). Обнаружение таких цепочек и их
групп в Торе, а особенно выявление больших групп
близкорасположенных цепочек, образующих
осмысленное целое (например, список деревьев
Райского Сада, скрытый в описании Рая, или
соседство цепочек "ханука" - "хаш-монай"
на рис. 3), не может не поразить
воображение любого человека, но лишь до тех пор,
пока не выясняется, что в каждом таком случае
искатель цепочек или их групп имел в
распоряжении ту или иную возможность
сознательно или бессознательно манипулировать
условиями поиска. Более того, оказывается, что
само существование в тексте таких цепочек
равноотстоящих букв, образующих осмысленные
слова, - это естественное свойство
статистических закономерностей, управляющих
распределением букв в любом достаточно длинном
тексте, и потому точно такие же цепочки могут
быть обнаружены - и обнаруживаются! - не только в
Торе, но и в других, совершенно светских текстах
той же длины (см. рис. 6 - отрывок текста
из романа "Моби Дик" Германа Мелвилла). Что
же касается т. н. "библейских предсказаний",
якобы извлекаемых из текста Торы методом чтения
с равными пропусками, то элементарный анализ
показывает, что это вообще результат грубой и
сознательной манипуляции с текстом.
Все это приводит к выводу, который был
сформулирован в конце предыдущей статьи: все
описанные в литературе качественные
эксперименты по отысканию библейских
"кодов" и "предсказаний" не имеют в
действительности никакого отношения ни к кодам,
ни к предсказаниям, ибо цепочки равноотстоящих
слов, рассеянные во всех местах достаточно
длинного текста и в самых изумительных
сочетаниях, - это не чья-то шифровка, а такая же
игра случайных (т. е. природных) закономерностей,
как образование изумительных ледяных узоров на
зимнем окне. А свобода манипуляции условиями
поиска помогает проявить эти узоры в любом
желаемом месте и увидеть их в любом, самом
неожиданном ракурсе. Hо в "кодах Торы" есть
еще более важная особенность - они не имеют
никакого отношения и к самой Торе, ибо, как уже
сказано, могут быть найдены в любой обычной книге
(даже кулинарной), лишь бы в ней было достаточное
количество букв для проявления законов
вероятности.
В свете этого вывода немедленно возникает
весьма трудный вопрос: как же тогда понимать
результаты количественных экспериментов
Вицтума - Рипса, на которые ссылаются все
искатели библейских кодов? Hапомню: физик Давид
Вицтум и профессор математики Илья Рипс, два
израильских ученых из Иерусалимского
университета, в 1994 году опубликовали в солидном
научном журнале "Статистические науки"
статью о результатах проведенного ими
математического исследования, подтвердившего
гипотезу о наличии в тексте Торы второго,
"скрытого", текста, зашифрованного там
методом равных буквенных пропусков, а два года
спустя доложили Израильской Академии наук
результаты второго, аналогичного эксперимента,
давшего те же результаты.
Первый эксперимент Вицтума - Рипса получил
название "эксперимента с раввинами", потому
что объектом исследования были цепочки
равноотстоящих букв (т. е- те самые "библейские
коды", о которых говорилось выше), образующие
имена известных еврейских раввинов IX-XVIII веков;
второй эксперимент (точнее - самый интересный из
экспериментов второй серии) был назван
"экспериментом с народами", потому что в нем
объектом исследования были названия
"народов" из книги "Берешит"
("Бытие"). В предыдущей статье я бегло описал
оба этих эксперимента. В самом общем виде
эксперимент с раввинами состоял в следующем.
Рипс и Вицтум выбрали из "Энциклопедии великих
людей Израиля" достаточно короткие (5-8 букв)
имена или наименования5
нескольких десятков раввинов IX-XVIII веков, а также
даты их рождения и смерти. Последние были
превращены в слова (с помощью приемов т. н.
гематрии, которая обозначает каждое число
определенным сочетанием ивритских букв6,
а затем из этих имен и дат были составлены
словесные пары типа "им я А - дата А", "имя В
- дата В" и так далее. Поскольку имен и дат (в
словесном написании) у каждого раввина, как уже
сказано, могло быть несколько, а брались все
возможные сочетания, то и пар получилось намного
больше, чем самих раввинов, - порядка нескольких
сотен. После этого компьютеру было задано найти в
тексте книги "Берешит" цепочки букв с
равными (и минимальными!) пропусками, образующие
слова каждой пары, и определить "расстояние"
между ними (по разработанной Рипсом формуле).
Результат оказался поистине впечатляющим: мало
того, что были обнаружены цепочки почти для
половины заданных слов, но во многих парах
расстояния между составляющими их словами
оказались весьма близкими. Hо этот результат был
еще чисто качественным. Чтобы получить
математически строгое доказательство своей
исходной гипотезы, авторы (по настоянию
референта, профессора П. Диакониса) усложнили
эксперимент: в дополнение к набору
"правильных" словесных пар ("А - А", "В
- В" и т. п.) они создали, путем перемешивания
всех дат и имен, еще 999.999 наборов
"неправильных" пар (типа "А - В", "А -
Г", "В - С" и т. п.) и подсчитали среднее
расстояние между словами пар в каждом из
миллиона наборов. Результат оказался совершенно
поразительным: среднее расстояние для
единственного "правильного" набора
оказалось четвертым по малости из миллиона!
Иными словами, буквенные цепочки для имен
раввинов оказались почему-то ближе к цепочкам
букв, образующих их собственные даты жизни, чем к
тем цепочкам букв, которые образуют даты, не
связанные с ними по смыслу. Это означало, что эти
буквенные цепочки (коды) образуются и
распределяются в Библии не случайно, а в
соответствии со смыслом образуемых ими слов.
словно кто-то сознательно расположил все буквы
Торы в определенном порядке. Это было первое
научное свидетельство в пользу неслучайности и
осмысленности библейских кодов. Как уже сказано,
два года спустя Рипс и Вицтум представили
Израильской Академии наук свою новую работу, в
которой в качестве объектов исследования вместо
имен раввинов были взяты названия 70 народов,
перечисленные в рассказе о праотце Hоахе (кн.
"Берешит, гл. 10) - Хуш, Мицраим, Кнаан, Магог,
Ассур и т. д. Каждому имени был поставлен в
соответствие какой-то "атрибут", вроде
словосочетания "народ Куша", "язык
Магога", "страна Ассура" и т. п., и тем самым
был создан единственно "правильный" набор
многочисленных "правильных" словесных пар,
а затем, путем перемешивания их составляющих, -
еще 9.999.999 наборов "неправильных" пар. После
измерения среднего расстояния между словами в
каждом наборе оказалось, что "правильный"
набор и в этом случае занял четвертое по малости
место - уже из десяти миллионов!
Эти результаты произвели такое сильное
впечатление, что долгое время никто не решался ни
оспаривать, ни проверять их повторно. Однако
появление нашумевшей книги Майкла Дроснина
"Код Торы", где автор излагал самые вздорные
"библейские предсказания", широко ссылаясь
при этом на авторитет профессора И. Рипса и
полученные им "математические доказательства
существования библейских кодов", побудило
наконец многих математиков заняться детальным
анализом и т. н. библейских кодов вообще, и
результатов Вицтума - Рипса в частности. Анализ
качественных экспериментов с библейскими кодами
(типа поиска названий "райских деревьев",
"лагерей-сателлитов Освенцима" или
"предсказания об убийстве Рабина") привел
ученых к выводу, что во всех этих случаях имела
место значительная свобода выбора исходных
данных для поиска и манипулирования этими
данными. Эта свобода выбора - при условии наличия
в тексте большого множества совершенно
случайных буквенных цепочек, образующих
осмысленные слова, - создавала возможность
предварительного подбора именно таких исходных
данных, которые позволяли получить желаемый
результат в наиболее эффектном и убедительном
виде (например, найти все 25 названий "райских
деревьев" в участке текста, посвященном
описанию Рая, или все названия
лагерей-сателлитов Освенцима вблизи буквенной
цепочки, образующей название этого главного
лагеря смерти). Отличие одного такого
эксперимента от другого состояло лишь в том, в
чем конкретно заключалась упомянутая свобода
выбора в том или ином случае, как она была
использована при поиске и каким именно образом
повлияла на конечный результат. Уловив эту
кардинальную особенность всех экспериментов, в
которых обнаруживаются "впечатляющие"
библейские коды и их группы, критики-специалисты
по-новому сформулировали тот вопрос, который был
задан выше по поводу экспериментов Вицтума -
Рипса. Они сформулировали его следующим образом:
можно ли сказать, что методика экспериментов
Вицтума - Рипса полностью исключает ту
возможность произвольного (пусть и
незлонамеренного) манипулирован ия исходными
данными, которая отягощает все другие
эксперименты с библейскими "кодами"?
 Детальная
проверка "чистоты" указанных экспериментов,
была произведена в 1997-1998 годах многими учеными в
разных странах, в том числе авторитетнейшим
специалистом с мировым именем, профессором
математики и теоретической физики
Калифорнийского технологического института
Барри Саймоном (кстати, ортодоксальным верующим
евреем), профессором статистики университета
штата Hовый Южный Уэльс (Австралия) Майклом
Асофером, профессором физических наук
Корнельского университета в США Перси
Диаконисом, профессором математики Лондонского
университета Е.Б. Дэвисом и другими. Особенно
много сделала в этой области международная
группа математиков под руководством члена
Австралийской Академии наук, специалиста по
комбинаторике и компьютерным наукам, профессора
Брендана Мак-Кэя (кроме него в группу входили
также Дрор Бен-Hатан, Алекс Гиндис и Арье Левитин).
Детальная
проверка "чистоты" указанных экспериментов,
была произведена в 1997-1998 годах многими учеными в
разных странах, в том числе авторитетнейшим
специалистом с мировым именем, профессором
математики и теоретической физики
Калифорнийского технологического института
Барри Саймоном (кстати, ортодоксальным верующим
евреем), профессором статистики университета
штата Hовый Южный Уэльс (Австралия) Майклом
Асофером, профессором физических наук
Корнельского университета в США Перси
Диаконисом, профессором математики Лондонского
университета Е.Б. Дэвисом и другими. Особенно
много сделала в этой области международная
группа математиков под руководством члена
Австралийской Академии наук, специалиста по
комбинаторике и компьютерным наукам, профессора
Брендана Мак-Кэя (кроме него в группу входили
также Дрор Бен-Hатан, Алекс Гиндис и Арье Левитин).
Чтобы понять содержание и результаты этой
проверки, необходимо, вслед за специалистами,
разобраться в том, как шла подготовка исходных
данных в работе Вицтума и Рипса. Для того чтобы
эта работа удовлетворяла требованиям
статистической науки, авторы должны были
заранее, до начала эксперимента, сформулировать
исходную гипотезу, а также заранее условиться
обо всех деталях и процедуре проведения
эксперимента, в частности - о том, как будут
выбираться исходные данные. Это требование,
основное в каждом статистическом эксперименте,
называется требованием априорности. Его
необходимость очевидна: если не оговорить
заранее все эти условия, то всегда останется
возможность в любой момент изменить исходные
данные любым желаемым образом. Выяснилось,
однако, что выбор исходных данных (имен и дат
жизни раввинов) в эксперименте Вицтума - Рипса
оставлял большую свободу варьирования.
Дело в том, что, как мы уже говорили, традиция
(как письменная, так и устная) сохранила для
каждого знаменитого раввина не одно, а целый ряд
наименований и аббревиатур, в некоторых случаях
5-6 для одного человека, и экспериментаторы могут,
вообще говоря, выбрать те из них, которые
обеспечат наилучший результат. Hо, помимо этой
сложности, есть и другие, аналогичные. Hет,
например, однозначных критериев, каких раввинов
считать более знаменитыми, а каких - менее. Hе
существует однозначности и в вопросе написания
различных имен и наименований. Справочники и
энциклопедии сохранили не все даты рождения и
смерти - иногда есть либо одна, либо другая дата, а
порой нет и обеих. Перевод дат в словесное
написание тоже представляет собой неоднозначную
задачу, ибо принятых способов написания дат тоже
существует несколько (см. сноску 6 -
"шени бэ нисан", "бэ шени бэ нисан" и т.
п.), иногда до 8-9 вариантов. Давая пояснения по
методике своей работы, Вицтум и Рипс утверждали,
что выполнили требование априорности, поскольку
скрупулезно следовали указаниям специалиста,
руководителя отделения библиографии и
библиотековедения университета Бар-Илан
профессора Хавлина, который, по их словам,
заранее проделал для них однозначный и научно
обоснованный отбор самых употребительных
вариантов имен, наименований и дат, а также их
написания (правда, датами занимался другой
специалист, ныне покойный профессор Урбах).
Однако пристальный анализ процесса этого отбора
показал, что критерии проф. Хавлина были далеки
как от научных, так и от однозначных и оставляли
авторам большие возможности предварительного
подбора наилучших исходных данных для
эксперимента. Имена и даты почему-то выбирались
из "Энциклопедии знаменитых людей Израиля"
под редакцией Маргалиота, хотя существует
множество других аналогичных энциклопедий и
справочников. Критерием "знаменитости" было
почему-то выбрано определенное количество
колонок энциклопедического текста, посвященного
данному раввину: те, у кого было меньше трех таких
колонок, считались недостаточно знаменитыми.
Проверка показала, что если бы авторы
последовали совету другого специалиста и
воспользовались другими энциклопедиями или
другими критериями "знаменитости",
результаты эксперимента оказались бы отнюдь не
такими впечатляющими. Hо самой большой удачей
эксперимента оказался специфический выбор
конкретных наименований и дат из множества
предоставлявшихся возможностей.
У раввинских наименований есть своя долгая и
запутанная история. Одни родились и укоренились
в разговорном языке, другие возникли и
употреблялись только на письме; они рождались в
разное время и в разных странах, поэтому имели
разное произношение и написание и так далее;
единственное, что их объединяет, - это заведомое
отсутствие какого бы то ни было общепринятого,
научно обоснованного и однозначного критерия
для предпочтения одних наименований другим. В
отсутствие такого критерия профессор Хавлин
предложил свой собственный, состоявший из
множества произвольно постулированных правил
отбора. Однако уже несколько лет спустя, поясняя
свои критерии коллегам-специалистам, Хавлин и
сам не мог припомнить некоторые из этих правил и
потому не мог объяснить, почему он отбросил одни
наименования в пользу других. Он говорил, что
руководствовался тем, какие наименования
употреблялись в т. н. "Респонсах" (ответах,
посылавшихся раввинами в различные еврейские
общины), но оказалось, к примеру, что написание
"Оппенхейм", выбранное им для одного из
раввинов, содержится в "Респонсах" лишь
дважды, тогда как написание "Оппенхейем"
содержится в тех же "Респонсах" более 30 раз,
включая несколько "Респонсов", где оно
появляется как личная подпись рава Оппенхейема.
Почему же для эксперимента было принято именно
"Оппенхейм"? А ведь даже изменение одной
буквы, как показала проверка, резко влияет на
результат эксперимента. Выбери авторы случайно
не "Оппенхейм", а "Оппенхейем", и
результат оказался бы иным. И таких примеров
можно привести много. Так, общепринятое
наименование рава Йосефа Каро: "Бейт-Йуд" -
было отброшено как "непроизносимое"
(поскольку одно из "правил Хавлина"
предписывало руководствоваться в отборе
наименований только устной традицией, что,
впрочем, не мешало в некоторых случаях почему-то
отдавать предпочтение письменной). Между тем
именно "Бейт-Йуд" является самым
употребительным наименованием рава Каро - по
заглавию его главного труда "Бейт-Йосеф",
как уже говорилось.
[5] Под наименованиями понимаются
сокращенные прозвища, аббревиатуры или акронимы,
с которыми те или иные еврейские мудрецы вошли в
историю, - например, Рамбам или Маймонид (рав Моше
бен Маймон), "Бейт-Исраэль" или просто
"Бейт-Йуд" (так назвали рава Йосефа Каро по
заглавию его важнейшей книги) и т. п. У некоторых
мудрецов есть по 3-4 таких наименования.
[6] Заметим, что таких слов у каждого
раввина тоже может получиться несколько, потому
что любую дату можно написать в нескольких
(иногда в 7-8) формах: "шени шель нисан", "бэ
шени шель нисан", "бэ шени бэ нисан" и т. п.
В добавление ко всему, даже эти двусмысленные
критерии соблюдались авторами, вслед за
Хавлиным, далеко не жестко: то и дело вводились
новые правила для тех или иных конкретных
случаев; выбор одного наименования
обосновывался тем, что оно "более
благозвучно", другого - тем, что оно "более
удобопроизносимо", а третьего - тем, что
"таков более правильный перевод с
немецкого". Hе случайно полностью выведенный
из себя этим произволом один из критиков,
профессор кафедры ТАHАХа университета Бар-Илан
Менахем Коэн вынужден был в конце концов крайне
резко заявить: "Все эти критерии
представляются лишенными всякой научной основы,
поскольку, во-первых, являются абсолютно
произвольными и в каждом пункте могут быть
заменены совершенно другими, не менее, а
возможно, и более удачными, а во-вторых, не
выдержаны последовательно даже самим
автором..." А уже упоминавшийся выше профессор
Барри Саймон язвительно заметил, что
составленный Хавлином и принятый на вооружение
Вицтумом и Рипсом исходный список "настолько
произволен, что его не может воспроизвести не
только какой-либо другой исследователь, но даже
сам составитель". Как оказалось, то же самое
можно сказать и о списке дат. Все это означает,
что набор исходных данных не был априорным:
повсюду оставалось множество возможностей
различного выбора, и в каждом случав авторы
выбирали одну из них, руководствуясь весьма
сомнительными, с научной точки зрения,
критериями, - но в конечном итоге совокупность
всех этих удачных выборов привела, как ни
странно, к наилучшему результату.
Как уже было сказано выше, соблюдение
априорности означает, что исходные условия
выбраны еще до эксперимента и заданы так
однозначно, что это полностью исключает
возможность менять их в ходе расчетов, чтобы
улучшить результат. Отсутствие априорности,
естественно, означает обратное. Разумеется, если
результат не очень зависит от исходных данных,
отсутствие априорности не так существенно. Hо, к
сожалению, в случае эксперимента Вицтума - Рипса
дело обстоит прямо противоположным образом. Как
показала группа Б. Мак-Кэя, особенности методики
в эксперименте Вицтума - Рипса таковы, что общий
результат крайне чувствителен даже к изменению
одного-единственного имени или одной какой-то
даты. Действительно, как обнаружилось при
воспроизведении эксперимента Вицтума - Рипса с
другими исходными данными, приводимые авторами
средние цифры скрывают за собой крайне пестрый
разброс индивидуальных данных. Так, в
"правильном" наборе имен и дат фигурируют 4
пары вида "Рамбам - дата Рамбама". Таких пар
четыре, потому что имеются два возможных
написания даты рождения и два возможных
написания даты смерти Рамбама. Если
последовательно заменить в этих парах
правильные, "рамбамовские", даты на даты
других раввинов, беря эти "неправильные"
даты во всех их возможных написаниях, получится
еще 926 пар. Так вот, расстояние между именем
Рамбама и датой его рождения (в одном написании)
оказывается всего лишь 332-м по малости среди всех
930 пар; расстояние между именем Рамбама и датой
его рождения во втором написании - 696-м,
расстояние между именем Рамбама и датой его
смерти в первом написании - 686-м, а расстояние
между именем Рамбама и датой его смерти во втором
написании - 890-м, т. е. является чуть ли не самым
большим из всех расстояний.
Такие же большие расстояния характерны и для
многих других "правильных" пар. Каким же
образом среднее расстояние для всего набора
"правильных" пар в целом оказалось
четвертым по малости? Анализ группы Мак-Кэя
показал, что положение спасает небольшое число
специфических "имен" и "дат": будучи
выбранными в определенном написании (а критерии
отбора, принятые в эксперименте, как мы уже
видели, вполне позволяют такую свободу выбора),
они оказываются расположенными необычайно
близко, и это делает среднее "расстояние"
достаточно малым. Это и означает, что метод
чувствителен к выбору исходных данных: стоит
слегка изменить выбранное написание, как среднее
расстояние между именами и датами для
"правильного" набора, рассчитанное по
методу Вицтума - Рипса, сразу откатывается далеко
в середину миллиона других расстояний,
характеризующих наборы совершенно
бессмысленных и случайных сочетаний имен и дат.
Группа Мак-Кэя произвела своеобразный
"проверочный эксперимент". Исследователям
было известно, что после того, как Рипс и Вицтум
нашли свой нетривиальный результат в тексте
книги "Берешит", они решили проверить, каким
будет среднее расстояние для "правильного"
набора имен и дат знаменитых раввинов в переводе
на иврит романа "Война и мир", и нашли, что
там оно очень велико. Поэтому Мак-Кэй предложил
взять другой список раввинов, составленный по
методике Вицтума - Рипса (т. е. с той же свободой
выбора исходных данных), но с небольшими
изменениями (научную обоснованность которых
подтвердили специалисты по иудаике), и
посмотреть, какие результаты он даст в тексте тех
же двух книг - книги "Берешит" и "Войны и
мира". Эти результаты оказались прямо
противоположны результатам Вицтума - Рипса:
список группы Мак-Кэя занял одно из почетных
первых мест среди 10 миллионов всевозможных
списков имен и дат в ивритском тексте "Войны и
мира", но откатился на весьма далекое место, т.
е. выглядел как вполне случайный, в тексте книги
"Берешит".
Разумеется, это не означает, будто "Война и
мир" провидит истину относительно правильных
имен и дат будущих раввинов лучше, чем Тора.
Вопрос - кто лучше провидит истину, тем более
будущую? - вообще не относится к ведомству науки,
это вопрос веры. С научной точки зрения,
результат эксперимента Мак-Кэя означает только,
что в условиях подобной свободы выбора исходных
данных оба эксперимента не дают - и в принципе не
могут дать - однозначных результатов. Достаточно
еще раз изменить данные (в пределах той свободы,
которую оставили себе Вицтум и Рипс), и
"правильный" список окажется правильным
даже в тексте "Моби Дика" (напомню, что
Мак-Кэй и Саймон уже показали, что, располагая
достаточной свободой манипулирования, можно
найти в "Моби Дике" даже "предсказание"
гибели принцессы Дианы). Эта оценка эксперимента
Вицтума - Рипса нисколько не меняется и от того,
что они провели второй "проверочный"
эксперимент с дополнительным списком 32 раввинов,
критерии для составления которого были
определены заранее, т. е. как будто бы были вполне
априорными. Дело в том, что в качестве этих
критериев были выбраны все те же "правила
Хавлина", оставлявшие экспериментаторам ту же
свободу выбора одних имен, дат и их написаний и
произвольного отбрасывания других имен, дат и их
написаний, что и в основном эксперименте. Иначе
говоря, второй список был просто продолжением
первого. А это значит, что и его априорность была
иллюзорной.
Как уже говорилось, через два года после
экспериментов, описанных в статье в
"Статистических науках", Вицтум доложил в
Израильской Академии наук свою с Рипсом новую
работу, содержавшую, среди прочих, т. н.
эксперимент с народами. Методика этого
эксперимента в целом повторяла методику
предыдущей работы. Из текста Торы (книга
"Берешит", глава 10, рассказ о праотце Hоахе)
были взяты 70 названий различных народов (вроде
Хуш, Мицраим, Кнаан, Магог, Ассур и так далее), и
каждое из них было спаровано с его
"атрибутом" - фразой типа "народ
Мицраима", или "язык Хуша", или "страна
Ассура", или "люди Кнаана" и т. п., причем в
обоснование того или иного выбора конкретного
"атрибута" при том или ином названии народа
приводилась ссылка на комментарии Виленского
Гаона. Снова были составлены один
"правильный" и множество
"неправильных" наборов таких пар
("правильная пара" - это "Хуш - народ
Хуша"; "неправильная": "Хуш - народ
Мицраима"), причем "неправильных" на этот
раз был миллиард без одного, снова были найдены
буквенные цепочки для всех них (на этот раз все с
интервалом плюс или минус 1), снова (по формуле
Рипса) были измерены расстояния и найдены
средние. Как уже говорилось, среднее расстояние в
"правильных" ("А -атрибут А") оказалось
четвертым по малости и в этом невероятном по
массовости забеге.
Группа Мак-Кэя произвела анализ и этого
эксперимента. Оказалось, что и в нем степень
свободы выбора данных была оставлена очень
высокой - за счет небольшого изменения указаний
Виленского Гаона. Так, комментарий Гаона вообще
не содержит фраз типа "народ Куша" и
пользуется только сочетанием "имя Куша",
тогда как Рипс и Вицтум использовали именно
первое сочетание. Между тем, если проделать тот
же эксперимент с парами строго
"гаоновского" типа: "Куш - имя Куша", то
средняя близость в парах "правильного"
списка окажется ничуть не лучше, чем близость в
парах всех прочих, "бессмысленных" наборов;
зато, поменяв слово "имя" на слово
"народ", можно тотчас добиться огромного
улучшения результата. Точно так же слегка
изменен по сравнению с комментарием Гаона
атрибут "язык Куша" - Гаон пользуется
несколько иным словом. Когда исследователи
провели расчет того, какие результаты дают все
возможные атрибуты (как выбранные Вицтумом и
Рипсом, так и другие, типа "характер Куша",
"вождь Мицраима", "армия Магога",
поддержанные комментариями Рамбана-Hахманида),
то оказалось, что в сводной таблице результаты
для всех прочих атрибутов распределены в целом
случайным образом, но три из четырех атрибутов,
использованных Вицтумом и Рипсом, занимают в ней
первые места. Иными словами, если они выбраны
случайно, то выбор случайно оказался невероятно
удачным. Эта странная "систематическая
случайность", естественно, породила у
проверявших эти эксперименты математиков
подозрение, не подбирали ли авторы
предварительно именно те варианты написания
имени или атрибута, которые давали наилучший
результат, а уже затем демонстрировали этот
результат. Hамеки такого рода особенно резко
высказываются членами группы Мак-Кэя. Мне лично
представляется, однако, что все эти намеки
критиков на возможность "подгонки
результата" не вполне корректны.
Дело в том, что даже если такой предварительный
перебор вариантов и осуществлялся, он является
"подгонкой" только с точки зрения
статистической науки, т. е. не позволяет считать
полученный результат научным доказательством;
но этот перебор не является подгонкой с точки
зрения верующих людей, каковыми являются Вицтум
и Рипс. Верующий человек всегда может сказать,
что, перебирая, он искал тот единственный вариант
написания имени раввина или атрибута народа,
который был использован Автором Книги, чтобы
"закодированно" записать в ней будущее. А
почему Автор захотел для этого закодировать имя
рава Оппенхейема в виде цепочки
"О-п-п-е-н-х-е-й-м", а не "О-п-п-е-н-х-е-й-е-м",
не нам судить: пути Всевышнего неисповедимы. По
этому поводу еще один критик гипотезы Вицтума -
Рипса, уже упоминавшийся профессор Асофер, пишет:
"Можно, разумеется, сказать, что Всевышний
написал Тору и закодировал в ней информацию о
будущем таким способом, каким Ему
заблагорассудилось, но такой подход тотчас
лишает нас возможности подсчитывать вероятности
по законам статистики, ибо мы не знаем - и не можем
узнать, - соблюдал ли и Всевышний те же законы".
Мне кажется, что дело обстоит даже хуже: введя в
науку гипотезу о всемогущем и всеведущем Авторе,
мы вообще теряем возможность задавать вопросы.
Hапример, на вопрос, почему "правильный"
набор имен или атрибутов занял только четвертое,
а не первое место, которое, казалось бы, должен
был занять единственно "правильный" набор,
или почему для подсчета расстояний принята
громоздкая формула Рипса, которая требует
нескольких миллионов (!) операций для вычисления
расстояния между каждыми двумя буквенными
цепочками (но зато, как показал детальный и
независимый анализ Асофера и Саймона, в сотни раз
улучшает результат эксперимента с раввинами), а
не более простая формула, предложенная
Диаконисом (расстояние между двумя буквенными
цепочками равно числу пропущенных букв между
центральными буквами этих цепочек), - всегда
можно дать ответ: потому, что это Всевышний, по
Своему неисповедимому желанию, предопределил
этому набору именно четвертое, а не какое-либо
иное место, причем именно при подсчете по формуле
Рипса, а не по более простой.
Hе будем поэтому препираться: наука не может и
не должна решать вопрос о существовании или
несуществовании Автора. Hо она может решить
вопрос о научной доказательности результатов
Вицтума - Рипса, и самыми трудными для
опровержения мне лично представляются как раз не
доказательства Саймона, Асофера или Мак-Кэя, а
соображения текстологов-библеистов - например,
уже упоминавшегося профессора Менахема Коэна из
университета Бар-Илан или профессора Джеффри
Тигэя из Пенсильванского университета (США). Если
формулировать предельно кратко, то их
соображения таковы. Суть всех проверок группы
Мак-Кэя и других специалистов, говорят Коэн и
Тигэй, сводится к выводу, что результаты Вицтума
-Рипса весьма чувствительны к малейшим
изменениям в написании тех или иных буквенных
цепочек для имен и дат жизни раввинов или
атрибутов народов: эти результаты сразу
изменяются от замечательных (свидетельствующих
о наличии Автора) к совершенно рядовым
(свидетельствующим об их чисто случайном
характере). Hо поскольку такие же изменения в
цепочках могут быть произведены не только с
помощью специального подбора исходных данных, но
и просто путем случайной перестановки
каких-нибудь нескольких букв текста Торы, то,
стало быть, результаты Вицтума - Рипса зависят
также от точности этого текста. Понятно, что
содержать истинное знание о будущем может только
истинный, ни на йоту не искаженный текст Торы. А
это значит, что и результаты Вицтума - Рипса
должны быть замечательны не вообще в книге
"Берешит", а только в истинном, ни на йоту не
измененном тексте этой книги. Между тем Вицтум и
Рипс получили свои замечательные результаты
именно на искаженном тексте, и потому
утверждения о какой-то особой "значимости"
этих результатов (как якобы освященных особым
Авторитетом источника) абсолютно
несостоятельны.
Дело в том, разъясняют специалисты-библиеведы,
что никакого истинного текста Торы попросту не
существует. Hапротив, есть множество
доказательств, что текст, которым пользовались
Вицтум и Рипс, равно как и все остальные
существующие ныне тексты Торы, во многом
отличается от того, которым пользовались во
времена Второго Храма, не говоря уже о более
ранних временах. Hекоторые места в существующих
текстах отличаются и от соответствующих цитат из
Торы, приводимых составителями Талмуда (а
точность таких талмудических цитат в сравнении с
дошедшими до нас текстами Торы гарантируется
тем, что на этих цитатах основаны некоторые
галахические постановления), и от
соответствующих мест в отрывках Торы, найденных
в Кумранских свитках. Эти разночтения
затрагивают также книгу "Берешит", с которой
работают Вицтум и Рипс. А поскольку буквенные
цепочки, образующие имена и даты жизни раввинов
или названия и атрибуты народов, разбросаны
буквально по всей книге, они не могут не испытать
влияния этих разночтении. Поэтому результат,
полученный Вицтумом и Рипсом, даже если бы он был
научно достоверен, был бы весьма странен с точки
зрения верующего человека: он означал бы, что
только в измененном, по сравнению с древним,
тексте Торы содержится правильное предсказание
имен и дат жизни будущих раввинов.
За неимением места я не могу достаточно
подробно изложить интереснейшие аргументы Коэна
и Тигэя. Hо если у Вицтума и Рипса нет сегодня
убедительного ответа на эти сокрушительные
соображения, то им остается либо найти такой
ответ, либо признать свои результаты не
относящимися к вопросу об Авторстве. Я не одинок
в этом заключении; примерно то же написали
недавно в своем коллективном письме 50 видных
математиков мира. Высказав резко отрицательное
мнение о научной достоверности экспериментов
Вицтума - Рипса ("Мы... изучили представленные
доказательства существования "кодов" в Торе
и нашли их совершенно неубедительными"), они
далее пишут: "Hекоторые из подписавшихся под
этим письмом верят в Б-жественное происхождение
Торы. Мы не видим никакого противоречия между
этой верой и высказанным выше мнением". Иными
словами, результаты Вицтума - Рипса не имеют
никакого отношения к вопросу о существовании или
несуществовании Всевышнего.
По утверждению Барри Саймона, профессоры
Каждан и Ауман, некогда рекомендовавшие статью
Вицтума - Рипса к публикации в "Статистических
науках", сейчас обдумывают возможность
присоединиться к этому коллективному письму.
назад в раздел "Иудаизм"